Vers le web sémantique
Après le web 2.0 et les réseaux sociaux, internet n’a pas fini d’évoluer. Une révolution discrète est en cours avec le web sémantique. À l’aide de langages communs qui structurent les données, il contribue à rendre interopérables les nombreuses bases de données en ligne.
Un web puissant mais limité
Le web tel que nous le connaissons, permet d’accéder à une multiplicité de pages sur internet. Ce web, qu’on peut qualifier de « web de documents », est certes utile et puissant, mais il rencontre ses limites quand il s’agit d’interroger des bases de données – des catalogues de bibliothèques par exemple – que les moteurs de recherche ne parviennent généralement à explorer qu’en surface. Ces bases de données constituent ce que l’on nomme le « web invisible ».
Autre limite du web actuel face aux bases de données : chaque base est très riche, mais elle ne communique pas avec les autres. De ce fait, si vous cherchez une information, vous devrez relancer votre recherche dans chaque base de données pour trouver ce qui vous intéresse. De plus, le catalogage de documents varie selon les types de bases et les différentes pratiques métier. Comme ces bases n’échangent pas leur données, il n’est pas possible de regrouper les informations qu’elles contiennent ou d’en extraire des données précises, recoupant une multiplicité de critères.

Vers le web sémantique
Le but du web sémantique est justement de permettre à un grand nombre de bases de données de communiquer, d’échanger des données et de s’enrichir mutuellement. En les structurant de façon identique, et en faisant en sorte que leurs données soient ouvertes (accessibles librement et gratuitement), les bases deviennent interopérables et peuvent faire converger leurs informations.
Sans constituer une rupture majeure avec le web que nous utilisons aujourd’hui – il est constitué d’urls et suit le protocole http – le web sémantique suppose de détailler les contenus au moyen de données descriptives finement structurées et liées entre elles. Cela peut faciliter les recherches d’informations en permettant avec une seule requête d’interroger plusieurs bases de données et ainsi d’obtenir des résultats beaucoup plus complets et précis.
Le web sémantique s’appuie sur un ensemble de règles normalisées et de standards informatiques, validés par le World Wide Web consortium (W3C) afin de favoriser le partage des données.
Web sémantique, web de données : comment ça marche ?
Le web sémantique repose sur deux conditions : l’exposition en ligne de données ouvertes et liées (Linked Open Data) et l’emploi d’un ensemble de standards informatiques qui permettent l’interopérabilité de ces données. Ces normes, appelées aussi vocabulaires descriptifs ou ontologies, décrivent la manière dont les données sont structurées, ce qui permet à différents systèmes informatiques de les réutiliser.
Les données du web sémantique sont structurées selon un modèle sujet-prédicat-objet, qu’on appelle un triplet RDF (ressource description framework) :
- le « sujet » représente la ressource à décrire ;
- le « prédicat » représente un type de propriété applicable à cette ressource ;
- l’« objet » représente une donnée ou une autre ressource : c’est donc la valeur de la propriété.
Par exemple :
- Victor Hugo (sujet) – est l’auteur de (prédicat) – Les Misérables (objet).
ou
- Victor Hugo (sujet) – est né à (prédicat) – Besançon (objet).
L’objet de chaque triplet peut à son tour devenir le sujet d’un nouveau triplet RDF :
- Les Misérables (sujet) – a été publié en (prédicat) – 1862 (objet)
ou
- Besançon (sujet) – est situé en (prédicat) – France (objet).
Dans le web sémantique, chaque partie de ce triplet est identifiée par une adresse url unique : l’uri, qui fait office de référence unique. Cela permet d’interroger ensemble une multitude de sources différentes en s’assurant que la donnée aura le même sens pour chacune des bases interrogées, qu’il s’agisse de bases de données biographiques, géographiques ou historiques.
Le schéma ci-dessous présente les nombreuses bases de données du web sémantique et les liens entre elles :
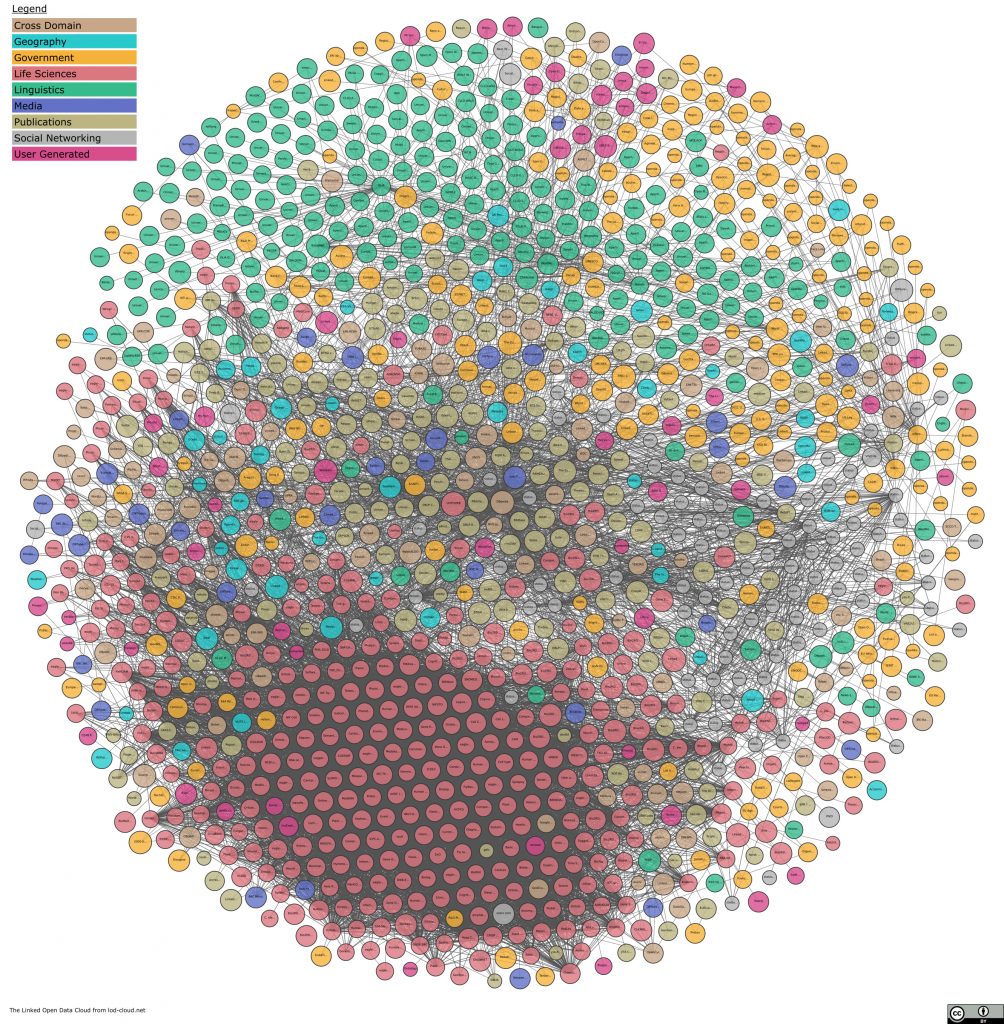
Le langage SPARQL (SPARQL Protocol and RDF Query Language) permet d’interroger le web sémantique. Les interfaces SPARQL sont encore complexes à prendre en main et nécessitent de bonnes connaissances préalables du web sémantique.
Néanmoins, les standards et les technologies du web sémantique sont de plus en plus utilisés, sans que les internautes s’en rendent toujours compte. De nombreuses bases de données, bibliothèques en ligne, mais aussi des sites marchands, s’en servent pour être plus visible sur le web et faciliter les recherches des internautes. Ainsi Google en fait usage pour faire remonter des informations. La structuration des données permet par exemple au moteur de recherche d’associer à un film son résumé, la liste des acteurs, ou les horaires de diffusion en salle.
Publié le 23/08/2021 - CC BY-SA 4.0


Data BNF
Data BNF est une base de données mise à disposition par la Bibliothèque nationale de France. Elle permet d’accéder à un ensemble de données sur les auteurs, les œuvres ou les thématiques. Outre les données produites par la BNF, DataBNF est enrichi avec des données provenant d’autres sources comme ISNI, VIAF, IdRef, Wikidata, etc.
Vous pouvez faire les recherches directement sur la base, ou extraire des données ré-utilisables, grâce à l’interface d’intérrogation SPARQL de Data BNF : https://data.bnf.fr/sparql/
Wikidata
Wikidata est une base de données libre et collaborative. Chacun peut y ajouter des données, dans une vingtaine de langues, pour enrichir celles existantes ou faire des liens avec d’autres jeux de données.
Vous pouvez rechercher directement sur Wikidata ou faire des recherches plus avancées et complexes en utilisant l’interface SPARQL de Wikidata à l’adresse : https://query.wikidata.org/
DBpedia
DBpédia présente un ensemble de données issues de Wikipédia et enrichies par différentes sources.
Web sémantique | CanalU
Ce cours en ligne de l’INRIA vous propose de vous former aux standards du Web de données et du Web sémantique. Il vous présentera les langages qui permettent : de représenter et de publier des données liées sur le Web (RDF), d’interroger et de sélectionner très précisément ces données à distance et au travers du Web (SPARQL), de représenter des vocabulaires et de déduire de nouvelles données pour enrichir les descriptions publiées et enfin, de tracer et de suivre l’histoire des données.
Les champs signalés avec une étoile (*) sont obligatoires